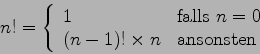Nächste Seite: 2.5 Effizienz von Algorithmen Aufwärts: 2. Allgemeines Vorherige Seite: 2.3 Wie formuliert man Inhalt
Weil die Rekursion in vielen Algorithmen eine zentrale Rolle spielt, soll hier kurz darauf eingegangen werden.
Unter Rekursion versteht man die Selbstbezüglichkeit eines Algorithmus oder eines (Teil-)Programms.
Das übliche Einstiegsbeispiel dazu: die Berechnung der Fakultät einer
natürlichen Zahl ![]() .
.
Die Fakultät einer Zahl ist das Produkt aller Zahlen von 1 bis
einschließlich der gegebenen Zahl ![]() , und wird mit einem
nachgestellten Ausrufezeichen markiert:
, und wird mit einem
nachgestellten Ausrufezeichen markiert:
(Die Fakultät von 0 hat per Definition den Wert 1.)
Neben dieser anschaulichen Definition kann man aber auch Teilausdrücke
zusammenfassen:
![]() , also
, also
![]() . Analog
ist
. Analog
ist
![]() , also
, also
![]() , und so
weiter; im allgemeinen Fall also
, und so
weiter; im allgemeinen Fall also
![]() oder
oder
![]() .
.
Damit hat man schon eine rekursive Definition der Fakultät:
Um jetzt die Definition auf alle natürlichen Zahlen zu erweitern,
braucht man eine Art Fallunterscheidung:
Die erwähnte Selbstbezüglichkeit drückt sich darin aus, daß zur
Definition der Fakultät bereits die Fakultät verwendet wird (im
Ausdruck
![]() ).
).
Typischerweise benötigt eine rekursive Definition immer einen
Ankerpunkt, der nicht rekursiv ist (hier für den Fall ![]() ).
).
Von manchen Algorithmen gibt es nur eine nichtrekursive Version, von manchen nur eine rekursive Version, es kann auch beide Versionen nebeneinander geben. Welche man dann auswählt, hängt hauptsächlich von der Effizienzbetrachtung ab.
Wenn beide Versionen existieren, dann wird die nichtrekursive Variante
meist iterativ genannt, weil in aller Regel jede
Selbstbezüglichkeit durch einen Iteration, also eine Wiederholung eines
Rechenschritts ersetzt wird (hier eine wiederholte Multiplikation
![]() ).
).
Die Umsetzung beider Versionen in ein Programm ist direkt möglich. Der iterativen Version aus Gleichung 2.1 entspricht folgendes Programmfragment:
int fakultaet_iterativ( int n )
{
int i;
int ergebnis;
ergebnis = 1;
for( int i=1; i<=n; i++ )
{
ergebnis *= i;
}
return ergebnis;
}
Dementsprechend kann die rekursive Variante aus Gleichung 2.2 so implementiert werden:
int fakultaet_rekursiv( int n )
{
if( n==0 ) return 1;
else return fakultaet_rekursiv( n-1 )*n;
}
Die rekursive Implementierung ist -wie so oft- bestechend kurz, einfach und prägnant, und kommt mit weniger Variablen aus. Trotzdem ist sie langsamer, und benötigt mehr Stackspeicher zur Laufzeit.
Nicht alle Programmiersprachen unterstützen rekursive Algorithmen; beispielsweise in FORTRAN und BASIC ist es nicht zulässig, Unterprogramme oder Funktionen direkt oder indirekt sich selbst aufrufen zu lassen.
Zumindest alle Sprachen mit einem modernen Konzept dagegen ermöglichen rekursives Programmieren: ALGOL, Pascal, C/C++, Java, und so weiter.
Wie ein rekursiver Funktionsaufruf technisch gesehen funktioniert, geht über dieses Skript hinaus. Wer sich dafür interessiert, muß sich anderweitig schlau machen. Sinnvoll ist das auf jeden Fall, weil ein Verständnis des Stacks vieles verständlicher macht, und vor allem heftige Programmierfehler vermeiden hilft (stack overflow, Sicherheitsprobleme durch buffer overrun).